SetRank
SetRank: Learning a Permutation-Invariant Ranking Model for Information Retrieval
SIGIR 2018 paper code 🌟paper reading list
Abstract
在IR的LTR中,排序模型从数据中自动学习然后对候选文档集进行排序,因此一个理想的排序模型应该是从文档集合到一个排列的映射,并且应该满足:(1)能够建模跨文档交互以捕捉query的local context information;(2)对于输入文档集合的任何排列输出结果应该是一定的。之前的LTR工作要么是学习一个单变量打分函数然后对每一个候选文档进行打分,因此不能对跨文档交互进行建模;或是构建一个多变量打分函数对文档序列进行打分,结果与输入顺序有关。
本文提出的SetRank是一种Neural LTR 模型,能够直接在任何规模的文档集合上学到与输入顺序无关的排序模型,采用了MSAB / IMSAB((induced) multi-head self attention blocks)的堆叠来学习query-doc的交互表达,自注意力机制不仅使得SetRank从跨文档交互中国呢捕捉local context information,同时也做到了顺序无关(因为本身self-attention是没有position信息的)。在Istella、MSLR 30k、Yahoo!三个数据集上的结果都优于传统LTR模型和SOTA的neural IR模型。
Approach
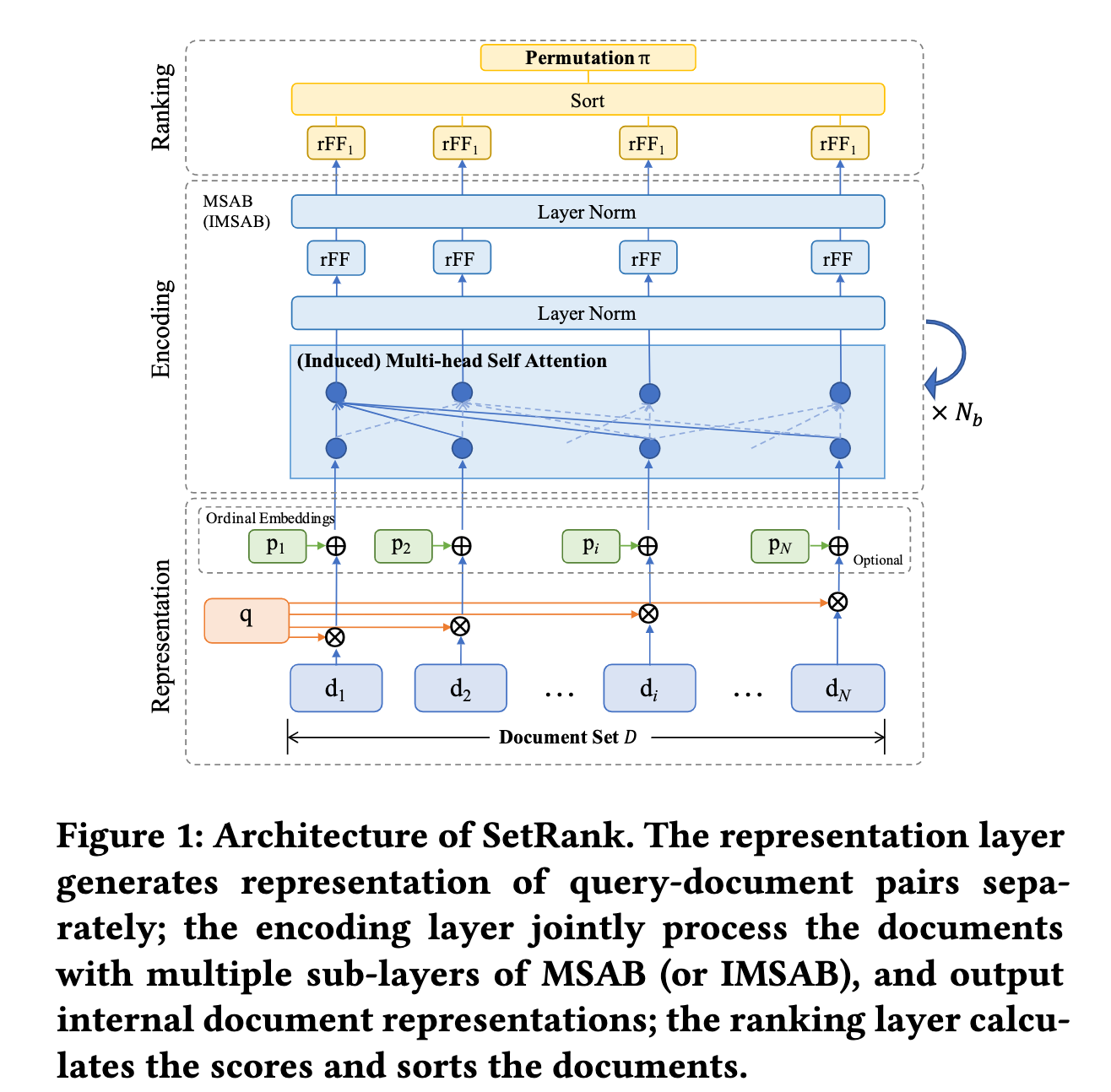
模型图如下:
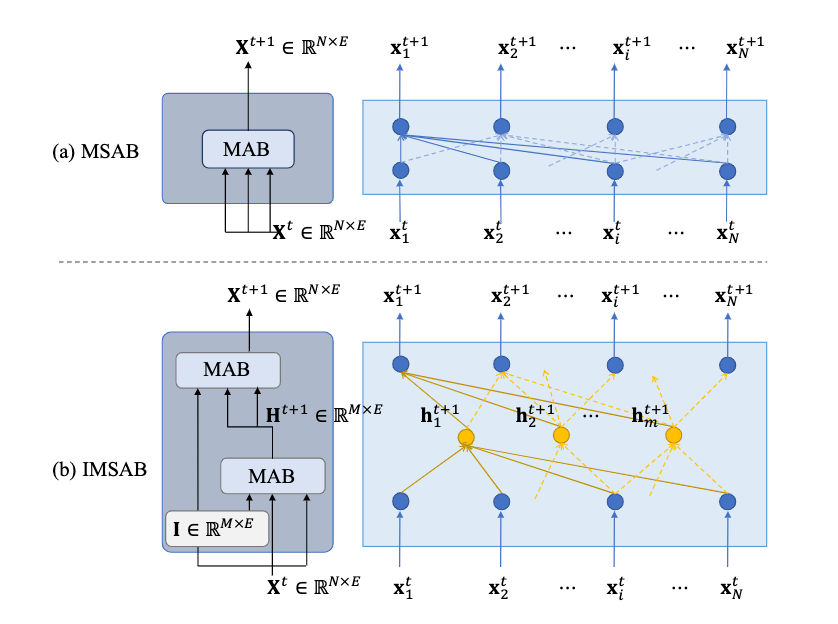
其中,IMSAB和MSAB结构如下
SetRank的pipeline结构由三部分构成:representation, encoding, ranking。
- 表示层对输入的每个文档分别表示为特征向量(传统LTR中用到的手工特征等),此外可以将初试排名做ordinal embedding,初始排名可以由现有的排名模型生成,如BM25或训练好的LambdaMART模型,可以同时嵌入多个初始排名列表的ordinal embedding;
- 编码层利用MSAB或IMSAB层的堆叠来做候选列表中文档的交互,利用相关文档的信息来丰富q-d表示;
- 排序层接收最顶层的MSAB(IMSAB)的输出,经过一层行前馈(rFF)得到所有文档的相关性分数,最后根据这些分数对文档进行排序。
Experiment

- 四种变体
- 置换不变性分析
- 文档集合大小影响分析
- 初始排名嵌入的分析
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!